
For the past few years, together with my team, I had the opportunity to build a brand-new AI Framework. A framework to power our future games at IO Interactive. To solve a lot of practical challenges, we utilized Data Oriented Design, when appropriate. I want to share what I learned. And I want to explore areas that I have not had a chance to dive in yet. I’ll do my best to explore the entire space as deep as my abilities allow it.
Although a lot of my experiences and opinions on the topic were formed during my time developing the AI Framework at IO Interactive, all opinions in this article are my own. I will use Data Oriented Design and DOD interchangeably. The same goes for Data Oriented Programming and DOP, Object Oriented Design and OOD, and Object Oriented Programming and OOP.
Who will Find this Article Useful?
If topics like CPU cache utilization, simpler to reason about code, clearer code, utilizing CPU cores and modularity are important for you, then you will find the information here useful.
My area of expertise is game development. The information here might be more beneficial to this domain compared to other types of software. C++ is used for so many software domain. And so, I can’t make a claim that the information in here applies universally for every single software product out there.
How to Consume this Article?
Another thing that you should consider before agreeing or disagreeing with anything in this article is that I do not consider myself the authority on this topic. I’m simply sharing my opinion that is entirely based on my experience in the gaming industry. Please, do not take my opinions in a personal way or for granted. Please, figure out what is important for the software you are working on. Do your own research, do your own measurements, and make your own conclusions.
Tools of the Trade
My preferred way of looking at OOD and DOD, and for that matter functional programming, is as bags of tools. Where each tool from the different bags can be used to solve a particular set of problems. This is really a cornerstone for the rest of the article and so I want to make sure it is very clear. I do not think of OOD and DOD as tools but rather as two collections of tools. This is a very important difference. When later in the article I disagree with abusing OOD principles, it does not mean that I condemn the language constructs used by OOD.
A Note on Code Examples
This article contains code examples. To make them nicely fit the page I had to shorten member or input variable names. The format of the code is also a bit differently than what I normally use.
1 – Data Oriented Design and Data Transformations
Diving deep in this topic is going to be a fantastic journey. And so, let us jump straight into to!
The way I like to think about Data Oriented Design is that it is just a way of thinking about programming where the data and the data transformations are front and center. It is important to mention the three components of the concept of data transformations. The first component is the source data and its format, called input. The second component is the target data and its format, called output. And the third component is the logical operation that takes the input, applies changes to the data and the format, and creates the output. DOD promotes data and logic separation. Furthermore, DOD promotes not only thinking about your input and output data just as a data set, but also how the data will be used after the transformation. The point is that we are not solving problems and doing transformations in a vacuum.
The following quote represents the core of how I personally think of Data Oriented Design, and Mr. Acton said it in such a perfect way that I can’t think of a way to improve on it. I can’t write an article about DOD without including this quote.
If you don’t understand the data, you don’t understand the problem. Understand the problem by understanding the data.
Mike Acton, Data Oriented Design and C++, CppCon 2014
1.1 – Elements of data oriented design
The problems we are solving are defined by the data. Transforming data is the act of solving the problem. The code we write to represent the transformation is the tool we use. And the hardware that executes the transformations brings us back to the physical reality and helps us pick the right tools for the job. Base on this, I would like to highlight the two very important elements that we have to consider when we create our data transformations: data and hardware.
1.1.1 – All we have is data and all we need to do is transform it
We often forget that as programmers, we constantly work with data and data is the most atomic unit in our software. This was never mentioned to me when I was studying programming. Instead young programmers are immediately taught how not to think about the data by overexposing them to all sorts of abstractions. In fact, I specifically remember being taught that code organization in object hierarchies is one of the most important skills I needed to learn as a student. I was also taught that the hardware evolves so very fast and that the compilers are getting smarter every day and I should focus on the code not on the data. Now, I believe all that to be, to put it mildly, a problematic way of looking at software. At least in my domain.
Everything is data. The pixels on the screen, the sound that our speakers produce, the text and fonts. The pictures and links of this article, the keyboard, mouse, and controller user input. The video feed that a Tesla Model 3 is using as an input for their AI model is also data. The mushrooms that Mario eats to grow and spit fireballs and the fireballs themselves. The blocks that Mario breaks with his fist, the levels and worlds and the pipes that Mario uses to travel. The remaining lives and the player score, and Mario himself. Instructions are data too. A very important piece of data. Instructions are stored in memory and they are fetched and transformed.
The first element of DOD is seeing our software as a collection of data that is changing and is transformed overtime.
1.1.2 – Learn about your hardware
In a physical sense, all data transformations must be executed somewhere. As programmers we have two choices when it comes to our data transformations running on physical hardware.
- Option 1: We can ignore the details that make the hardware. A lot of software is supposed to run on different hardware. If we can write our code in abstract ways and without thinking of the range of hardware we are supporting, then our jobs as programmers becomes easier. This way we decouple hardware knowledge from software knowledge. The bar for new programmers gets lower, meaning more programmers joining the workforce.
- Option 2: We take time to educate ourselves on the range of hardware our data transformations will be running on. By having this knowledge, we can at the very least make the most critical data transformations take advantage of the hardware. This means that as programmers, we are expected to have both software and hardware knowledge. This means that the bar for new programmers is higher.
In DOD, we take Option 2. We want to get closer to the optimal performance. For that, we educate ourselves about the hardware that will execute the transformations, in addition to understanding the data and how it needs to be transformed. And we use the language features, which are just tools, to write code that will help the hardware do the transformation in the most efficient way.
To illustrate this, let’s consider the differences of creating software for a gaming console, a mobile device and a server machine. In the gaming industry for example, we deploy games on all of these. On a console, we will likely be trying to utilize as much of all cores as possible. We do that to run one single game. On a server machine, it is common that we run an entire game world (the server side of our games) with many players, only on one core. This way we can utilize all cores for many game worlds. On mobile devices, we share the limited CPU, and battery resource with many apps running on the background. Often a “race to sleep” approach is utilized to reduce battery usage.
And so, understanding how the hardware works and knowing the range of supported hardware is the second element of DOD.
1.2 – Core pillar of programming
The idea of organizing our code from the point of view of the data transformations is not a new idea. The very base type of work that we do, as programmers, is data transformations. We take an input that we transform into an output. Everything we do, be that on a small or big scale, can be broken down into a data transformation followed by data transformation, followed by another one, and so on. Data transformations are the core pillar of programming since the inception of our craft and the very first computers.
The Data Oriented Design way of thinking focuses on the actual data and its format. We do this in a way where we build logical operations to operate on very concrete data formats and produce other very concrete data formats.
I will contrast DOD with OOD to better explain DOD. Object Oriented Design promotes abstraction, while DOD often leads to the removal of abstractions and to more closely modelling our software to take advantage of the particular details of the set of hardware we are supporting. It is important to also mention that like everything else, abstractions are sometimes useful too.
1.3 – Look for the most statistically common data transformations
A common misconception about Data Oriented Design is that it is all about cache utilization. In reality, this is only part of it and cache utilization is not only about general guidelines but most importantly it is about understanding your exact problem. It is about separating hot and cold data. DOD encourages us to find a set of most statistically common data transformations and implement them using different transformation pipelines. The common OOD approach is the opposite. It encourages us to abstract the operation as much as possible in the name of code organization and a generic solution that can handle as many use cases as possible.
A very good examples to illustrate this comes from Mike Acton’s Data Oriented Design and C++ talk at CppCon 2014 (a link to the talk can be found at the end of the article). I would like to dive a bit deeper on it.
1.3.1 – Consider the following problem:
Imagine having a game object that you can move in your game world. Now imagine that there are two very common use cases that will cause objects to move.
- Objects can move while the game is running and while the players are having fun playing the game. These objects will most likely be moved with unique 3D translations per object.
- Objects can also be moved during edit time in our game editor, as the game levels are being created by designers. Objects in bundles will most likely be moved with the same 3D translation.
And of course, we care about performance. Moving objects around is one of the most common things we do in game engines. We need to do it fast because there are many and more complicated, and expensive problems our games need to solve.
1.3.2 – Let’s consider the OOD solution:
Both of these cases are conceptually the same, but in reality, they are quite different. The most statistically common scenario during runtime is for very few of the game objects to move each frame. And most statistically common scenario during edit time it is for hundreds, if not thousands, of objects to be moved around in a bundle. If we look at this problem with OOD lenses we can immediately see a way to simplify it. We merge both cases by having an Object class and we write a single function that moves an object. We can then use that function in both scenarios. Here is a code sample that illustrates this:
class Object
{
public:
// Constructor
Object(const Vector3D& inPosition,
const Quaternion& inOrientation);
// Methods
void SetOrientation(const Quaternion& inOrientation)
{
m_Orientation = inOrientation;
}
void Translate(const Vector3D& inTranslation)
{
m_Position += m_Orientation * inTranslation
}
//...more methods
//...and even more methods
private:
//...other data
//...other data
Vector3D m_Position;
Quaternion m_Orientation;
//...other data
//...other data
//...other data
//...other data
};Let’s think critically about how we simplified the problem. We ignored the reality that these two cases exist and actually we did not simplify the problem at all. We changed it and invented another problem that we solved in a bad way. Our original problem still exists. We still want to be able to optimally move a massive bundle of objects with the the same 3D translation. And we still want to be able to optimally move a few objects with unique 3D translations per object.
For the sake of keeping this example as simple as possible, I did something really bad. I generalized all game objects as one problem. The reality is that the problem I described above has even more depth and cases to consider. For example, moving covers markup objects in our editor in a bundle could be very different than moving static geometry in a bundle. Also, an object hierarchy might be in place and that hierarchy might influence the translation, depending on what the user wants.
It is likely that the covers markup object will have extra data. It will likely have an extra behavior of associating the cover with the closest static geometry and checking if the cover is valid. Often in OOD, the difference is only considered from point of view of the behavior. The expectation is that the specific cover implementation of the “void Translate(const Vector3D& inTranslation)” function will deal with the extra details about the behavior. The real difference, which is the data format, is not considered.
1.3.3 – Let’s consider the DOD solution:
Same as before, let’s just ignore the fact that an object hierarchy might be in place. We will also ignore the fact that there might be other types of objects, like cover markup, that will require a different way of moving them around. Please do not ignore details like these in production code, we are doing it just to simplify the example.
// objects_store.h
struct ObjectsStore
{
vector<Vector3D> m_Positions;
vector<Quaternion> m_Orientations;
};// Runtime solution:
struct TranslationData
{
Vector3D m_ObjPosition;
const Quaternion m_ObjOrientation;
const Vector3D m_ObjTranslation;
};
void PrepareTranslations(const ObjectsStore& inStore,
const vector<Vector3D>& inTranslations,
vector<TranslationData>& outObjectsToTranslate)
{
assert(inStore.m_Positions.size() == inStore.m_Orientations.size());
assert(inStore.m_Positions.size() == inTranslations.size());
for (size_t i = 0; i < inTranslations.size(); ++i)
{
outObjectsToTranslate.push_back
({
inStore.m_Positions[i];
inStore.m_Orientations[i];
inStore.inTranslations[i];
});
}
}
void TranslateObject(vector<TranslationData>& ioObjectsToTranslate)
{
for (TranslationData& data: ioObjectsToTranslate)
data.m_ObjPosition += data.m_ObjOrientation * data.m_ObjTranslation;
}
void ApplyTranslation(const vector<TranslationData>& inTranslationData
ObjectsStore& outStore)
{
assert(inStore.m_Positions.size() == inTranslationData.size());
for (size_t i = 0; i < inTranslationData.size(); ++i)
outStore.m_Positions[i] = inTranslationData[i].m_ObjPosition;
}
void UpdateGame(ObjectsStore& ioStore, vector<Vector3D>& inTranslations)
{
vector<TranslationData> translation_data;
PrepareTranslations(ioStore, inTranslations, translation_data);
TranslateObject(translation_data);
ApplyTranslation(translation_data, ioStore);
}// Edit time solution:
void TranslateObjectEdittime(vector<Vector3D>& ioObjectPositions,
const Quaternion& inOrientation,
const Vector3D& inTranslationLocalSpace)
{
// This translation vector is in world space
const Vector3D translation = inOrientation * inTranslationLocalSpace;
for (Vector3D& position: ioObjectPositions)
position += translation ;
}
void UpdateEditor(ObjectsStore& inStore,
const Quaternion& inOrientation,
const Vector3D& inTranslation)
{
TranslateObject(inStore.m_Positions, inOrientation, inTranslation);
}We recognized that there are two problems we need to solve. And we solved them in different ways. And so instead of having a class that represents an object, we will have an objects store. The store contains synchronized arrays that hold the different parts of the objects data.
The solution for the runtime problem packs the data needed for the computation in a continuous block of memory. Most importantly, the data format closely follows the problem definition. Each object is moved with a unique translation. To be more specific, first we need to call the “PrepareTranslations(…)” function to pack the data in the needed format, then we need to call the “TranslateObject(…)” function to process the packed data and to make the translation. And finally, we call the “ApplyTranslation(…)” function to apply the translations to the objects store.
The solution for the edit time problem is simple because the problem is simple. This is a very important observation. This solution also reflects the problem in the way the data is formatted and passed to the function. Objects in a bundle are all translated with the same translation and direction. In this case we don’t need to prepare and apply the transformations as in the runtime case. We can directly work on the store data because it happens to already be in the correct format.
The DOD code is more than the OOD code. No point in denying that. I personally find the code much clearer though, but I’m used to seeing this kind of code. I can better understand what work is being done and the cost of it. And I can better understand the two statistically common cases and why they exist. This code is closer to the actual problem and hardware than the typical OOD variant. We will talk a lot more about this later in this article.
2 – Pros of Using Data Oriented Design
2.1 – Clearer code
In my experience, Data Oriented Design often leads to clearer code in the form simple structures to store data and compact for loop with no branching. This might sound counter intuitive to someone that is not used to DOD. Clearer code means easier to understand by other programmers and it means less buggy. It means that it is easier for other programmer to understand the problem the code is solving. It also means that it is easier to understand the most statistically common data transformations that are occurring in our software. Of course, it means easier to modify and improve. And of course, it means easier to test, be that unit testing, integration testing or manual testing. Later in the article, we are going to examine the effects of DOD in a complete example.
2.2 – CPU cache utilization

The image is a simplified representation of how many cycles it takes for the CPU to access data, based on where that data is in our memory (Registers, L1 Cache, L2 Cache, RAM). The word “simplified” here is very important. The cycles needed to access memory from the different locations are representative, and of course there are differences depending the CPU model and hardware architecture. The diagram doesn’t take into account details like having multiple cores, core with their own L1 Cache, cores that share L2 Cache. It doesn’t take into account how memory moves from RAM to L2 and to L2, and so on. Some processors even have an L3 Cache.
The important detail is that loading from RAM is slow. In fact, much slower than some of the heavy math operations, like SQRT. Every time our data is not in the caches, we are paying the ultimate cost. How we organize our data and code is of extreme importance to the speed of execution.
Data Oriented Design naturally achieves better performance because it promotes CPU cache utilization. In reality, there is no rule to force us to arrange our data and instructions in a cache friendly way but then again, DOD is a way of thinking and not a set of rules. When approaching a problem in a DOD way, we end up organizing our input data in chunks that are continuously placed in memory. Without going in too many details, the logical operations that transform the input data into output data will often process the the data in a for loop, thus utilizing the cache efficiently. The topic of memory access and cache utilization deserves a full article on its own, and so I will create one in the future.
It is also important to mention memory alignment here. In my experience, using DOD leads to naturally organizing my data in a way where the compiler doesn’t have to pad my structs. I can’t remember a case where I needed a bool in a data structure used by a DOD code. Cache misses that are partially caused by padded data structures are some of the worst. Paying for loading dummy data is completely useless.
When we talk about cache utilization, we cannot ignore branching. While branching is a cornerstone of programming, it should be avoided at all cost in performance critical loops. Again, Data Oriented Design promotes this by pushing us to make sure that the data is already prepared and in the correct format. This way our critical for loops can iterate on it to produce an output without branching. Branching is unavoidable, but we should always prefer to branch as early as possible. This always leads to the CPU having to do less. This is one of the best optimizations we can utilize. Further in the article, we will see an example of this in action.
2.3 – Multithreading
Data Oriented Design makes it fairly easy to utilize parallelization. I acknowledge that parallelization is not always available for every target hardware and product. But to those of us that can utilize it, DOD can help us. In my opinion, data access is the most important thing we must consider when parallelizing our software.

The following diagram maps references between objects. Each arrow represents some sort of a reference to another object that could be of the same or a different type. This kind of dependency graph can be found in every big codebase. Utilizing multiple threads to speed up a particular, or multiple, data transformation on a dependency graph like this is quite hard. Sometime it might not even be worth it if we have to carpet-bomb our code with synchronization primitives.
We talked about how the concept of input, output and the logical operations that convert the input to the output are front and center when we talk about DOD. The data access can be controlled and reasoned about very easily. This means that by organizing our data transformation pipelines with our data in mind, we can fairly easy achieve parallelization because of the clear data dependencies. In my experience, we can quite often parallelize code based on DOD principles without using any synchronization primitives. This is yet another topic that deserves a full article. I’ll make sure to cover it in the future.
We should also mention False Sharing. There is nothing that prevents you from getting the negative effects of False Sharing in DOD code. That being said, in my experience, it is much easier to spot it. And to begin with, it is easier to prevent it. Again, this is another very interesting topic that we cannot fully cover here. Herb Sutter covers is quite well in this article.
2.4 – Modularity
Data Oriented Design naturally encourages us to architect our complex systems in a very modular way. The components of our complex systems can be arranged in a data flow pipeline. And we can make them interact with each other through inputs and outputs. Effectively making them black-boxes. Similarly, multiple complex systems can interact with each other in exactly the same way. We can achieve a very high level of modularity because of this. I find this topic extremely fascinating and I’ll definitely write an in-depth article about it in the future.
2.5 – Code that is easy to reason about
Data Oriented Design allows us to reason about complex problem if we organize them in a data transformation pipeline. By recognizing the most statistically common cases, we can do simple back of the envelop estimation of the data passing through our systems. We can easily measure the cost of each transformation. And we can easily understand our data access and spot opportunities for parallelization. And finally, we can easily figure out what we need to do in case we need to change or upgrade our systems.
3 – Cons of Using Data Oriented Design
Personally, I have found two drawback to Data Oriented Design.
In all fairness, the first one is caused by the overwhelming popularity of OOD in the last few decades. Young programmers are fed a steady diet of OOD and abstractions. And they are taught to not be aware of the data and the hardware. And I know this because it wasn’t too long ago when I was fed that same diet. It takes time to change your way of thinking. And it is hard to achieve a mind shift on a personal level, not to mention on a team or an organization level.
The second one has to do with overusing or overengineering simple problems. DOD does not mean utilizing ECS everywhere. But this is the first instinct and what people reach out for when initially introduced to this way of thinking. The vast majority of problems where DOD is applicable do not need complicated frameworks. A solution like ECS does not come for free and in fact it is a sort of an abstraction too.
I’m struggling listing more drawbacks, since DOD is away of thinking and should be used when appropriate. One could argue that there are more drawbacks to Data Oriented Design. Allegedly, it is hard to interface DOD with already existing OOD code. Allegedly DOD code is hard to debug. Next, let us talk about these two and other myths.
4 – Myths about Data Oriented Design
4.1 – Myth 1: DOD code is hard to interface with OOD code
By hard, people mean many things. It sometimes means more code, or because you have to switch between different mindsets, or because OOD or DOD code might leak into each other.
I’ll give an anecdotal evidence, but all of the information I’m sharing in this article is based on my personal experience. For a few years, my team and I were developing a new AI framework. A framework heavily based on DOD, to power our future games at IO Interactive. An already existing AI framework was powering the games we were working on (Hitman 2016 and Hitman 2) at the time.
We started plugging in parts of the new framework as they became ready to be used. The interface between the old and the new AI frameworks was fairly easy. The reason for that was because we did it with a few small data format conversion systems. That systems were very small, just a few for loops and some very small utility functions. The time it took for us to implement them was negligible. and in terms of having bugs, I can’t remember even one. The new AI framework code did not leak into the old one, and vise versa.
Let us take the vision sensor and the entire vision pipeline of the Hitman 2 NPCs which was powered by the new AI framework. The new vision pipeline would output the result in a format that we wanted for the new AI framework, but we wrote a small data converter that will transform that data to the data format needed by the old framework. The cost of the converter was almost undetectable by the profiler, so that was not a problem as well. The new AI framework will run the new vision pipeline at an appropriate point in the frame. Then the old framework will pick up the converted vision of the data and use it. It was that easy to interface the two vastly different and massive frameworks.
4.2 – Myth 2: DOD code is hard to debug
When I ask people, what makes DOD hard to debug, I always get the same answer. Which is that all the data pieces that represent the same object are scattered all over the place and that it is very hard to inspect all properties associated with a single object. There are two reasons behind this myth.
4.2.1 – First reason
In DOD it makes no sense to say that the data that represents an object is scattered all over the place. There is no such thing as “all the data” and “objects” when we write DOD code with the right mindset. There are only inputs, logical operations that execute data transformations, and outputs. This myth comes from the fact that people try to apply OOD thinking when using DOD. At the end of the day this only leads to producing OOD code. I will lie if I say that this is something I have never done. On the contrary, I have done this quite a lot as I was originally learning about DOD. It takes time and it is a mindset shift that is not easy to execute.
4.2.2 – Second reason
When you debug a problem in DOD code, you never need to see “all the data”. Every time I end up debugging DOD code the process is always the same:
- I start by reasoning about what is wrong, and by wrong, I mean identifying the piece of data I was expecting and confirming that the data I have is not as expected.
- Then I reason about where that specific piece of data I’m interested in is created. In DOD, it is always the case that the data I’m expecting is the output of some logical operation somewhere in my code. Most often than not you can easily track the data transformation to a single function.
- Then I place a breakpoint in the identified location where the data transformation takes place and I inspect the logic, step by step.
I never care about “all the data”. I always care about the subset of data that is wrong and that is causing the bug. Of course, a bug might be caused by a few chained problems, but even then you don’t need to see “all the data” to figure it out. I just keep applying the steps I described to identify more places where relevant to the problem data is being transformed.
In a sense, “all the data” would generate a lot of noise that is actually making it harder to
solve the problem and debug.
4.3 – Myth 3: DOD is a programming pattern or a modeling approach
Data Oriented Design is neither a programming pattern or a modelling approach. Patterns or modelling approaches exist to create abstractions. Writing DOD code, removes abstractions.
4.4 – Myth 4: DOD and Entity Component System (ECS) are synonyms
ECS is a concrete way of organizing data in components and logical operations in systems. Systems execute the data transformations on the components. ECS is based on DOD, but these two are not synonyms. You don’t need to use ECS to be able to utilize a DOD approach to solving problems. The reality is that, as a solution, ECS is an overkill for quite a lot of cases. When solving problems in a DOD way, I often reach for way simpler tools than ECS, regardless of the fact that I have access to a working ECS framework. We will discuss ECS in future articles, it is a very interesting topic to cover.
4.5 – Myth 5: DOD is good and OOD is evil
Object Oriented Design is just a bag of tools, similarly to DOD. In fact, all language constructs are useful for certain problems. Classes and inheritance are useful, virtual functions are useful, templates are useful, and so on. DOD gives us a different set of tools in our toolbox that we can use. One could argue that OOD is very overused and can lead to both complexity and performance problems, but any tool can be overused. The hard part is to develop an internal heuristic to know which tool to use for the right job and to never adopt extreme stances.
I highly recommend this presentation and its follow-up, as an example of how you can use the concept of Objects, while utilizing a custom allocator and DOD principles.
5 – Don’t Model Software After the Real World
I want to get one last thing off my chest before we start applying DOD and solve an actual problem, which we will also measure in terms of performance.
For some reason programmers are using OOD in a weird way, by trying to represent the software components as objects modeled after the real world. Ask yourself, why do we have to model software after the real world?
Modeling software based on the real world allows the problem domain to enter and be fully represented in the software. In my experience, doing this while using heavy abstractions always leads to bringing the model of the view or the model of the world as a context for the problem itself. This is just noise. The problem is the problem and it is already well defined by the input data and the expected output data. Noise is bad when we are dealing with already complicated data transformations. Noise moves us away from the problem itself and it often leads to the invention of other problems we do not have.
Composing data that does not belong together in an object so we can have a class that we can name a Character for example, does not help us in any way. In fact, it often masks the impact of the different data fields in the object. Adding deep inheritance to the problem makes it even worse. Now we don’t even know what data we are carrying with the derived class. Doing this and adding layers of abstractions tends to make things extremely complicated and entangled.
Consider the following quote:
I think the lack of reusability comes in object-oriented languages, not functional languages. Because the problem with object-oriented languages is they’ve got all this implicit environment that they carry around with them. You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.
Joe Armstrong, creator of Erlang
Let’s consider an example. Say we have a game with three types of characters, Player character, Guard NPC, and Civilian NPCs. For those not familiar with NPC, it means Non-Player Character. The following is a typical example of how these could be implemented in an OOD way:
class CharacterBase
{
public:
// Constructors
// Destructor
// Pure virtual methods
// Virtual methods
// Methods
private:
// Private methods
// Private data
protected:
// Protected data
};class PlayerCharacter : public CharacterBase
{
public:
// Constructors
// Destructor
// Virtual override methods
// Methods
private:
// Private methods
// Private data
};class GuardNPC: public CharacterBase
{
public:
// Constructors
// Destructor
// Virtual override methods
// Methods
private:
// Private methods
// Private data
};class CivilianNPC: public CharacterBase
{
public:
// Constructors
// Destructor
// Virtual override methods
// Methods
private:
// Private methods
// Private data
};This example is not even doing justice to what we find in our code bases every day, I’ve seen much deeper inheritance, with many interfaces involved.
Fundamentally the three concepts (player, guards, and civilian characters) are so vastly different from each other. Of course, all of them have some data, like world position, that is identical, but so do many other types of objects. There is some utility code that is shared, but we do not need an object hierarchy to facilitate that. The vast amount of data and code that would make these different types of characters is so different.
Solving problems for the player characters is one thing considering that there is one such character in the game, assuming we are talking about a single player game. Solving problems for the civilian characters is a totally different thing, considering we might have thousands of them instantiated all at ones. And finally solving problems for the guard characters is yet another totally different problem, considering that they need to have a much better sensors and decision making, and much deeper behaviors than the civilian character, but also considering that there is usually around 30-400 of them (depending on the game) all instantiated at the same time. All of these are data problems, and not code organization problems.
The problems we need to solve when it comes to the civilian characters are orders of magnitude different from the problems guard and player characters have. Similarly, the problems we need to solve for the guards are orders of magnitude different from the problems of the civilian and player characters. Why would we want to bind all of them to a common base class, or many base classes? In my experience, bad OOD foundation and practice push programmers in a funnel and asks them to reach for the same set of tools no matter what the problem is. This is not helpful.
We do not need to build the real world constructs into the code because they don’t belong there. Parts of the real world context belong in the Creative Design Documents and the rest in the Technical Design Documents. A benefit of DOD mindset is that it considers the data as facts. When we discard noise and unnecessary context from our data, it reduces the complexity and the chance of entangling code and data that otherwise don’t belong together.
6 – Applying Data Oriented Design
Let’s put everything we talked about together and examine how we can solve a problem by focusing on the data. I’ll also include a small section about how we will solve the same problem using OOD concepts. We will examine the differences, and most importantly we will measure the results. You can find a link to the full source code at the end of the article.
6.1 – Test Case
Let us assume that we have a small game with cars. Each car can drive around, it can be damaged and can run out of fuel.
I’ll implement 3 different OOD inspired solutions and one typical DOD. After that we will measure the performance. Then we will try to apply the DOD mindset to reason about and optimize the OOD inspired solutions with the goal to show that DOD is truly a way of thinking and can be combined with OOD. We will of course measure the improved OOD solutions as well.
Note that this article is pretty big and I need to make the test case fairly trivial. Its purpose is to raise questions that you should answer on your own in your own code bases. This example captures both good and bad extremes for both OOD and DOD. In that sense, production code is not a clean cut, like this test case is.
6.1.1 – Car Properties:
- Identifier: Let’s assume that each object in our game world, no matter if it is a car or something else needs to have some sort of an identifier so the engine knows about the existence of that object and can refer to it through this identifier.
- Car manufacturer and model info: Let’s assume that each car needs to hold information about the manufacturer and the model the car is. This will be useful information to show in our game UI.
- Activation state: Let’s assume that in our engine, each object (and that includes the cars) needs to support an activated and deactivated state. For example, we could decide to implement some sort of an LOD where we deactivate cars that are very far away from the player.
- Position: The cars will have a location in our 2D world. The location is represented by a 2D point.
- Direction: The cars will have a direction in our 2D world. The location is represented by a normalized vector and it describes what is the current movement direction.
- Speed: The cars will have a speed that tells us how fast the car is moving.
- Remaining fuel: The car will have a fuel container. For the purpose of this example, we only have petrol cars. If the car is left without fuel, then it can’t move.
- Fuel consumption info: This describes how much fuel is consumed per meter.
- Remaining health: The car will have health. The car can be damaged to a point where it cannot function anymore. This happens if the health reaches 0.
6.1.2 – Simulation:
We are not going to write a full game, but rather we will make a small simulation that will do the following:
- We will create X number of cars.
- Every other car is going to be deactivated (say, because they are too far away from the player).
- We will simulate 60 game frames.
- Every frame, we will damage all activated cars by the same amount. Eventually all cars’ health will reach 0.
- Every frame, we update all relevant components of each activated car:
- Steering
- Speed
- Movement
- Fuel
6.2 – Approach 1: All data in one object, no inheritance and using continuous memory
All of the car related memory will be on the heap in a continuous block. For the purpose of this example, I’m simulating an object that was implemented without thinking about the data. We will improve on it later and see how this small class can also perform well. That being said, in my experience, I have seen a lot of code implemented in this or similar ways.
// car.h
class Car
{
public:
// Constructor
Car(const uint64_t inID,
const Vector2D& inPosition,
const Vector2D& inDirection);
// Modification API
void UpdateSteering(const float inDrivingWheelAngle);
void UpdateSpeed(const float inModification);
void UpdateMovement(const float inDeltaTime);
void TakeDamage(const float inDamage);
void SetToActivated();
void SetToDeactivated();
// Query API
bool IsActivated() const;
bool IsDead() const;
bool HaveFuel() const;
private:
// Car data
const uint64_t m_ID;
CarInfo m_CarInfo;
bool m_IsActivated;
Vector2D m_Position;
Vector2D m_Direction;
float m_Speed;
float m_RemainingFuel;
float m_FuelPctConsumptionPerMeter;
float m_RemainignHealth;
};// car.cpp
Car::Car(const uint64_t inID,
const Vector2D& inPosition,
const Vector2D& inDirection)
: m_ID(inID)
, m_CarInfo(GetRandomCarInfo())
, m_IsActivated(true)
, m_Position(inPosition)
, m_Direction(inDirection)
, m_Speed(0.0f)
, m_RemainingFuel(100.0f)
, m_FuelPctConsumptionPerMeter(2.0f)
, m_RemainignHealth(100.0f)
{
}
void Car::UpdateSteering(const float inDrivingWheelAngle)
{
if (IsActivated() && HaveFuel() && !IsDead())
m_Direction.RotateDeg(inDrivingWheelAngle);
}
void Car::UpdateSpeed(const float inModification)
{
if (IsActivated() && HaveFuel() && !IsDead())
m_Speed += inModification;
}
void Car::UpdateMovement(const float inDeltaTime)
{
if (IsActivated() && HaveFuel() && !IsDead())
{
const float frame_speed = m_Speed * inDeltaTime;
const Vector2D new_position = m_Position + m_Direction * frame_speed;
const float distance_traveled = (m_Position - new_position).Length();
m_RemainingFuel -= distance_traveled * m_FuelPctConsumptionPerMeter;
m_Position = new_position;
}
}
void Car::TakeDamage(const float inDamage)
{
m_RemainignHealth -= inDamage;
}
void Car::SetToActivated()
{
m_IsActivated = true;
}
void Car::SetToDeactivated()
{
m_IsActivated = false;
}
bool Car::IsActivated() const
{
return m_IsActivated == true;
}
bool Car::IsDead() const
{
return m_RemainignHealth <= 0.0f;
}
bool Car::HaveFuel() const
{
return m_RemainingFuel > 0.0f;
}// simulation.cpp
void Simulation(const unsigned int inNumOfFramesToSimulate,
const unsigned int inNumOfCars)
{
vector<Car> cars;
cars.reserve(inNumOfCars);
PrepareSimulation(inNumOfCars, cars);
ExecuteSimulation(inNumOfFramesToSimulate, inNumOfCars, cars);
}
void PrepareSimulation(const unsigned int inNumOfCars, vector<Car>& outCars)
{
for (unsigned int car_index = 0; car_index < inNumOfCars; ++car_index)
{
// Create a car
// We use random values because they don't matter for this example
const uint64_t id = RandInt();
const auto pos = Vector2D(RandFloat(), RandFloat());
const auto dir = Vector2D(RandFloat(), RandFloat()).Normalized();
outCars.emplace_back(Car(id, pos, dir));
// Deactivate every other car
if (car_index % 2)
outCars[car_index].SetToDeactivated();
}
}
void ExecuteSimulation(const unsigned int inNumOfFrames,
const unsigned int inNumOfCars,
vector<Car>& inCars)
{
// Random inputs used by the simulation.
const float steering_input = RandFloat(-2.5f, 2.5f);
const float speed_modification = RandFloat(0.0f, 0.2f);
for (unsigned int update_idx = 0; update_idx < inNumOfFrames; ++update_idx)
{
const float delta_time = GetDeltaTime();
for (unsigned int car_index = 0; car_index < inNumOfCars; ++car_index)
{
// Damage every other car
if (car_index % 2 == 0 && !ioCars[car_index].IsDead())
inCars[car_index].TakeDamage(7.0f);
// Update the current car
inCars[car_index].UpdateSteering(steering_input);
inCars[car_index].UpdateSpeed(speed_modification);
inCars[car_index].UpdateMovement(delta_time);
}
}
}This is a very typical small class where we combine the data and the logic together.
Notice that in order to produce this solution we did not have to think at all about our data or the hardware. We left the details of how our code will perform to the universe to deal with.
Notice that there is no function to update the fuel consumption. I did this in the UpdateMovement(…) function. I intentionally modeled it that way to illustrate a very common pattern that I have observed. In this particular case, in order to calculate the fuel consumption for the current frame, we need to know what distance the car traveled. We can easily compute that information in the UpdateMovement(…) function. People tend to merge problems when they have access to all the data of the class, and they tend to write convenient rather than good code. This issue looks so minor and innocent in a small example like this. I’ll leave it to you to imagine the result of 6 or 12 months of iteration on the same code and piling things on top of each other for convenience.
We will measure the performance of the ExecuteSimulation(…) function for all approaches.
6.3 – Approach 2: All data in one object, no inheritance and using non-continuous memory
For this example, we will reuse the car class defined earlier and we only change the simulation code. We are simulating the case where the cars in the array are allocated on the heap and not in a continuous block. This happens very often, especially when objects can be instantiated based on user input.
In the “Simulate(…)” function, I have added three dummy arrays. The reason is to make sure that I allocate memory in between allocating the memory of the cars we are going to use for the simulation. This is just a simple way for me to make sure the cars for the simulations are not allocated continuously.
// simulation.cpp
void Simulation(const unsigned int inNumOfFramesToSimulate,
const unsigned int inNumOfCars)
{
// Storage for the cars
vector<unique_ptr<Car>> cars;
// Storage for dummy cars.
vector<unique_ptr<Car>> dummy_cars1;
vector<unique_ptr<Car>> dummy_cars2;
vector<unique_ptr<Car>> dummy_cars3;
cars.reserve(inNumOfCars);
PrepareSimulation(inNumOfCars, cars, dummy_cars1, dummy_cars2, dummy_cars3);
ExecuteSimulation(inNumOfFramesToSimulate, inNumOfCars, cars);
}
void PrepareSimulation(const unsigned int inNumOfCars,
vector<unique_ptr<Car>>& outCars,
vector<unique_ptr<Car>>& outDummyCars1,
vector<unique_ptr<Car>>& outDummyCars2,
vector<unique_ptr<Car>>& outDummyCars3)
{
for (unsigned int car_index = 0; car_index < inNumOfCars; ++car_index)
{
// Create a car
// We use random values because they don't matter for this example
const uint64_t id = RandInt();
const auto pos = Vector2D(RandFloat(), RandFloat());
const auto dir = Vector2D(RandFloat(), RandFloat()).Normalized();
outCars.emplace_back(make_unique<Car>(id, pos, dir));
// Deactivate every other car
if (car_index % 2)
outCars[car_index]->SetToDeactivated();
// Create the dummy cars
dummy_cars1.push_back(make_unique<Car>(id, pos, dir));
dummy_cars2.push_back(make_unique<Car>(id, pos, dir));
dummy_cars3.push_back(make_unique<Car>(id, pos, dir));
}
}
void ExecuteSimulation(const unsigned int inNumOfFrames,
const unsigned int inNumOfCars,
vector<Car>& inCars)
{
// Random inputs used by the simulation.
const float steering_input = RandFloat(-2.5f, 2.5f);
const float speed_modification = RandFloat(0.0f, 0.2f);
for (unsigned int update_idx = 0; update_idx < inNumOfFrames; ++update_idx)
{
const float delta_time = GetDeltaTime();
for (unsigned int car_index = 0; car_index < inNumOfCars; ++car_index)
{
// Damage every other car
if (car_index % 2 == 0 && !ioCars[car_index].IsDead())
inCars[car_index].TakeDamage(7.0f);
// Update the current car
inCars[car_index].UpdateSteering(steering_input);
inCars[car_index].UpdateSpeed(speed_modification);
inCars[car_index].UpdateMovement(delta_time);
}
}
}6.4 – Approach 3: All data in one object, with inheritance and using non-continuous memory
This final OOD example defines a slightly different class for the car. We are using inheritance. Similarly to the previous example, we are simulating the case where the cars in the array are allocated on the heap and not in a continuous block.
// car.h
class CarBase
{
public:
// Constructor
CarBase(const uint64_t inID,
const Vector2D& inPosition,
const Vector2D& inDirection);
// Destructor
virtual ~CarBase() = default;
// Modification API
virtual void UpdateSteering(const float inDrivingWheelAngle) = 0;
virtual void UpdateSpeed(const float inModification) = 0;
virtual void UpdateMovement(const float inDeltaTime) = 0;
void SetToActivated();
void SetToDeactivated();
void TakeDamage(const float inDamage);
// Query API
bool IsActivated() const;
bool IsDead() const;
private:
// Private base car data
const uint64_t m_ID;
bool m_IsActivated;
float m_RemainignHealth;
protected:
// Base car data
CarInfo m_CarInfo;
Vector2D m_Position;
Vector2D m_Direction;
float m_Speed;
};
class PetrolCar : public CarBase
{
public:
// Constructor
PetrolCar(const uint64_t inID,
const Vector2D& inPosition,
const Vector2D& inDirection);
// Destructor
virtual ~PetrolCar() = default;
// Modification API Override
virtual void UpdateSteering(const float inDrivingWheelAngle) override;
virtual void UpdateSpeed(const float inModification) override;
virtual void UpdateMovement(const float inDeltaTime) override;
// Additonal Query API
bool HaveFuel() const;
private:
// Fuel data
float m_RemainingFuel;
float m_FuelPctConsumptionPerMeter;
};// car.cpp
CarBase::CarBase(const uint64_t inID,
const Vector2D& inPosition,
const Vector2D& inDirection)
: m_ID(inID)
, m_CarInfo(GetRandomCarInfo())
, m_IsActivated(true)
, m_RemainignHealth(100.0f)
, m_Position(inPosition)
, m_Direction(inDirection)
, m_Speed(0.0f)
{
}
void CarBase::SetToActivated()
{
m_IsActivated = true;
}
void CarBase::SetToDeactivated()
{
m_IsActivated = false;
}
bool CarBase::IsActivated() const
{
return m_IsActivated;
}
void CarBase::TakeDamage(const float inDamage)
{
m_RemainignHealth -= inDamage;
}
bool CarBase::IsDead() const
{
return m_RemainignHealth <= 0.0f;
}
PetrolCar::PetrolCar(const uint64_t inID,
const Vector2D& inPosition,
const Vector2D& inDirection)
: CarBase(inID, inPosition, inDirection)
, m_RemainingFuel(100.0f)
, m_FuelPctConsumptionPerMeter(2.0f)
{
}
void PetrolCar::UpdateSteering(const float inDrivingWheelAngle)
{
if (IsActivated() && HaveFuel() && !IsDead())
m_Direction.RotateDeg(inDrivingWheelAngle);
}
void PetrolCar::UpdateSpeed(const float inModification)
{
if (IsActivated() && HaveFuel() && !IsDead())
m_Speed += inModification;
}
void PetrolCar::UpdateMovement(const float inDeltaTime)
{
if (IsActivated() && HaveFuel() && !IsDead())
{
const float frame_speed = m_Speed * inDeltaTime;
const Vector2D new_position = m_Position + m_Direction * frame_speed;
float distance_traveled = (m_Position - new_position).Length();
m_RemainingFuel -= distance_traveled * m_FuelPctConsumptionPerMeter;
m_Position = new_position;
}
}
bool PetrolCar::HaveFuel() const
{
return m_RemainingFuel > 0.0f;
}// simulation.cpp
void Simulation(const unsigned int inNumOfFramesToSimulate,
const unsigned int inNumOfCars)
{
// Storage for the cars
vector<unique_ptr<CarBase>> cars;
// Storage for dummy cars.
vector<unique_ptr<CarBase>> dummy_cars1;
vector<unique_ptr<CarBase>> dummy_cars1;
vector<unique_ptr<CarBase>> dummy_cars1;
cars.reserve(inNumOfCars);
PrepareSimulation(inNumOfCars, cars, dummy_cars1, dummy_cars2, dummy_cars3);
ExecuteSimulation(inNumOfFramesToSimulate, inNumOfCars, cars);
}
void PrepareSimulation(const unsigned int inNumOfCars,
vector<unique_ptr<CarBase>>& outCars,
vector<unique_ptr<CarBase>>& outDummyCars1,
vector<unique_ptr<CarBase>>& outDummyCars2,
vector<unique_ptr<CarBase>>& outDummyCars3)
{
for (unsigned int car_index = 0; car_index < inNumOfCars; ++car_index)
{
// Create a car
// We use random values because they don't matter for this example
const uint64_t id = RandInt();
const auto pos = Vector2D(RandFloat(), RandFloat());
const auto dir = Vector2D(RandFloat(), RandFloat()).Normalized();
outCars.emplace_back(make_unique<PetrolCar>(id, pos, dir));
// Deactivate every other car
if (car_index % 2)
outCars[car_index]->SetToDeactivated();
// Create the dummy cars
dummy_cars1.push_back(make_unique<PetrolCar>(id, pos, dir));
dummy_cars2.push_back(make_unique<PetrolCar>(id, pos, dir));
dummy_cars3.push_back(make_unique<PetrolCar>(id, pos, dir));
}
}
void ExecuteSimulation(const unsigned int inNumOfFrames,
const unsigned int inNumOfCars,
vector<CarBase>& inCars)
{
// Random inputs used by the simulation.
const float steering_input = RandFloat(-2.5f, 2.5f);
const float speed_modification = RandFloat(0.0f, 0.2f);
for (unsigned int update_idx = 0; update_idx < inNumOfFrames; ++update_idx)
{
const float delta_time = GetDeltaTime();
for (unsigned int car_index = 0; car_index < inNumOfCars; ++car_index)
{
// Damage every other car
if (car_index % 2 == 0 && !ioCars[car_index].IsDead())
inCars[car_index].TakeDamage(7.0f);
// Update the current car
inCars[car_index].UpdateSteering(steering_input);
inCars[car_index].UpdateSpeed(speed_modification);
inCars[car_index].UpdateMovement(delta_time);
}
}
}6.5 – Approach 4: Data split in arrays with helper transient data
And finally, let us look at the DOD solution and examine how we will organize our data and code.
We start by defining a store for all our cars. The store contains all data for all cars. Updating the cars happen in the “UpdateCars(…)” function, which internally uses a bunch of utility functions defined as free functions in the .cpp. The store also contains transient data, used by the transformation pipeline defined in the “UpdateCars(…)” function. The transient data is cleared at the end of each frame, and its only purpose is to serve as an intermediate data format that the update pipeline is using to optimally execute the data transformations. The definition of the transient data is in the .cpp file as it is not needed to be publicly available.
// cars_store.h
// Forward declaration
//
// Stores one frame transient data. This is intermediate data used by the update
// pipeline every frame and discarded at the end of the frame.
// Note that this class in defined in the .cpp file because only
// the store needs to see it.
namespace Details
{
struct CarsStoreTransientData;
}
// Stores all car related data
class CarsStore
{
public:
// Car active state
enum class State
{
Activated,
Deactivated
};
// Constructor
CarsStore();
// Destructor
~CarsStore();
// Public modification API
void CreateCar(const uint64_t inID,
const Vector2D& inPosition,
const Vector2D& inDirection);
void SetCarToActivedState(const unsigned int inCarIndex);
void SetCarToDeactivatedState(const unsigned int inCarIndex);
void DamageCar(const unsigned int inCarIndex, const float inDamage);
// Public update API
void UpdateCars(const float inDeltaTime,
const vector<float>& ioSteeringData,
const vector<float>& ioSpeedModificationData);
// Public query API
bool IsCarActivated(const unsigned int inCarIndex) const;
bool DoesCarHaveFuel(const unsigned int inCarIndex) const;
bool IsCarDead(const unsigned int inCarIndex) const;
private:
// Store data
unsigned int m_NumOfCars;
vector<uint64_t> m_IDs;
vector<State> m_ActivationStates;
vector<Vector2D> m_Positions;
vector<Vector2D> m_Directions;
vector<float> m_Veloctities;
vector<float> m_Fuel;
vector<float> m_FuelConsumptionPerMeter;
vector<float> m_HealthData;
vector<CarInfo> m_InfoData;
// Stores one frame transient data. This is intermediate data used by the
// update pipeline every frame and discarded at the end of the frame
unique_ptr<Details::CarsStoreTransientData> m_TransientData;
};Here is the definition of the transient data that is defined in the store .cpp. I find this technique very useful. Forward declare the transient data in the .h file but define it in the .cpp file. Then, have a unique pointer to the transient data. We allocate the memory in the store constructor. In my book, this is nearly perfect encapsulation and a very useful approach.
// cars_store.cpp
// Helper structs to store parts of the transient data
struct FuelDataForCarsToUpdate
{
float m_RemainingFuel;
const float m_FuelConsumptionPerMeter;
const float m_DistanceTraveled;
};
struct MovementDataForCarsToUpdate
{
Vector2D m_Position;
const Vector2D m_Diretion;
const float m_Speed;
float m_DistanceTraveled;
};
// Stores one frame transient data
// This is intermediate data used by the update pipeline every frame and discarded
// at the end of the frame.
struct CarsStoreTransientData
{
vector<unsigned int> m_CarsToUpdate;
vector<Vector2D> m_DirectionsToUpdate;
vector<float> m_VelocitiesToUpdate;
vector<MovementDataForCarsToUpdate> m_MovementDataForCarsToUpdate;
vector<FuelDataForCarsToUpdate> m_FuelDataForCarsToUpdate;
void Clear()
{
m_CarsToUpdate.clear();
m_DirectionsToUpdate.clear();
m_VelocitiesToUpdate.clear();
m_MovementDataForCarsToUpdate.clear();
m_FuelDataForCarsToUpdate.clear();
}
};The first set of functions we are going to look at are the public modification API. Although the “UpdateCars(…)” function is part of this API, we will look at it on its own because it requires special attention. One thing that should stand out is that the modification functions need the index of the car we want to modify.
// cars_store.cpp --> Public modification API
CarsStore::CarsStore()
: m_NumOfCars(0)
, m_TransientData(make_unique<CarsStoreTransientData>())
{
}
void CarsStore::CreateCar(const uint64_t inID,
const Vector2D& inPosition,
const Vector2D& inDirection)
{
m_IDs.push_back(inID);
m_Positions.push_back(inPosition);
m_Directions.push_back(inDirection);
m_Veloctities.push_back(0.0f);
m_Fuel.push_back(100.0f);
m_FuelConsumptionPerMeter.push_back(2.0f);
m_ActivationStates.push_back(State::Activated);
m_HealthData.push_back(100.0f);
m_InfoData.push_back(GetRandomCarInfo());
++m_NumOfCars;
}
void CarsStore::SetCarToActivedState(const unsigned int inCarIndex)
{
m_ActivationStates[inCarIndex] = State::Activated;
}
void CarsStore::SetCarToDeactivatedState(const unsigned int inCarIndex)
{
m_ActivationStates[inCarIndex] = State::Deactivated;
}
void CarsStore::DamageCar(const unsigned int inCarIndex, const float inDamage)
{
m_HealthData[inCarIndex] -= inDamage;
}Next, let us have a look at the public query API.
// cars_store.cpp --> Public query API
bool CarsStore::IsCarActivated(const unsigned int inCarIndex) const
{
return m_ActivationStates[inCarIndex] == State::Activated;
}
bool CarsStore::DoesCarHaveFuel(const unsigned int inCarIndex) const
{
return m_Fuel[inCarIndex] > 0.0f;
}
bool CarsStore::IsCarDead(const unsigned int inCarIndex) const
{
return m_HealthData[inCarIndex] <= 0.0f;
}Now, let’s look at the “UpdateCars” function. This function is the core of the store in terms of data transformations. It represents the update pipeline and the data transformations that take place. The code is very simple and well commented and it should be able to follow what is going on.
// cars_store.cpp --> Public update API
void CarsStore::UpdateCars(const float inDeltaTime,
const vector<float>& ioSteeringData,
const vector<float>& ioSpeedModificationData)
{
// Select which cars need to be updated this frame
SelectCarsToUpdate
(
*this,
m_NumOfCars,
m_TransientData->m_CarsToUpdate
);
// Prepare the directions data of the cars that need to be updated
PreapareDirectionsToUpdate
(
m_TransientData->m_CarsToUpdate,
m_Directions,
m_TransientData->m_DirectionsToUpdate
);
// Update the directions data of the cars selected for update
UpdateSteering
(
inDeltaTime,
ioSteeringData,
m_TransientData->m_DirectionsToUpdate
);
// Prepare the velocities data of the cars that need to be updated
PreapareVelocitiesToUpdate
(
m_TransientData->m_CarsToUpdate,
m_Veloctities,
m_TransientData->m_VelocitiesToUpdate
);
// Update the velocities data of the cars selected for update
UpdateSpeed
(
inDeltaTime,
ioSpeedModificationData,
m_TransientData->m_VelocitiesToUpdate
);
// Prepare the movement data of the cars that need to be updated
PreapareMovementDataForCarsToUpdate
(
m_TransientData->m_CarsToUpdate,
m_Positions,
m_Directions,
m_Veloctities,
m_TransientData->m_MovementDataForCarsToUpdate
);
// Update the movement data of the cars selected for update
UpdateMovements
(
inDeltaTime,
m_TransientData->m_MovementDataForCarsToUpdate
);
// Prepare the fuel data of the cars that need to be updated
PreapareFuelForCarsToUpdate
(
m_TransientData->m_CarsToUpdate,
m_Fuel,
m_FuelConsumptionPerMeter,
m_TransientData->m_MovementDataForCarsToUpdate,
m_TransientData->m_FuelDataForCarsToUpdate
);
// Update the fuel data of the cars selected for update
UpdateFuel
(
inDeltaTime,
m_TransientData->m_FuelDataForCarsToUpdate
);
// Copy the transient data into the store data
const auto& t = m_TransientData;
unsigned int data_index = 0;
for (unsigned int car_idx : trd->m_CarsToUpdate)
{
const auto& dir = t->m_DirectionsToUpdate[data_idx];
const auto& vel = t->m_VelocitiesToUpdate[data_idx];
const auto& pos = t->m_MovementDataForCarsToUpdate[data_idx].m_Position;
const auto& fuel = t->m_FuelDataForCarsToUpdate[data_idx].m_RemainingFuel;
// Apply the values
m_Directions[car_idx] = dir;
m_Veloctities[car_idx] = vel;
m_Positions[car_idx] = pos;
m_Fuel[car_idx] = fuel;
++data_index;
}
// Clear the transient data and make it ready to be used for the next frame
m_TransientData->Clear();
}And this is the implementation of utility functions doing small data transformations. Notice how each data transformation operates on a continuous block of memory formatted specifically for the data transformation in question. Also notice that with the exception of “SelectCarsToUpdate()” none of the data transformations are branching. Also notice how before each critical data transformation, we prepare the data for it.
// cars_store.cpp --> Private update API
void SelectCarsToUpdate
(
const CarsStore& inStore,
const unsigned int inNumOfCars,
vector<unsigned int>& outCarsToUpdate
)
{
for (unsigned int car_index = 0; car_index < inNumOfCars; ++car_index)
{
if (inStore.IsCarActivated(car_index) &&
inStore.DoesCarHaveFuel(car_index) &&
!inStore.IsCarDead(car_index))
{
outCarsToUpdate.push_back(car_index);
}
}
}
void PreapareDirectionsToUpdate(const vector<unsigned int>& inCarsToUpdate,
const vector<Vector2D>& inDirections,
vector<Vector2D>& outDirectionsToUpdate)
{
for (unsigned int car_index : inCarsToUpdate)
outDirectionsToUpdate.push_back(inDirections[car_index]);
}
void UpdateSteering(const float inDeltaTime,
const vector<float>& ioSteeringData,
vector<Vector2D>& outDirectionsToUpdate)
{
unsigned int index = 0;
for (Vector2D& direction : outDirectionsToUpdate)
direction.RotateDeg(ioSteeringData[index++]);
}
void PreapareVelocitiesToUpdate(const vector<unsigned int>& inCarsToUpdate,
const vector<float>& inVeloctities,
vector<float>& outVelocitiesToUpdate)
{
for (unsigned int car_index : inCarsToUpdate)
outVelocitiesToUpdate.push_back(inVeloctities[car_index]);
}
void UpdateSpeed(const float inDeltaTime,
const vector<float>& ioSpeedModificationData,
vector<float>& outVelocitiesToUpdate)
{
unsigned int index = 0;
for (float& speed : outVelocitiesToUpdate)
speed += ioSpeedModificationData[index++];
}
void PreapareMovementDataForCarsToUpdate
(
const vector<unsigned int>& inCarsToUpdate,
const vector<Vector2D>& inPositions,
const vector<Vector2D>& inDirections,
const vector<float>& inVeloctities,
vector<MovementDataForCarsToUpdate>& outMovementDataForCarsToUpdate
)
{
for (unsigned int car_index : inCarsToUpdate)
{
outMovementDataForCarsToUpdate.push_back
({
inPositions[car_index],
inDirections[car_index],
inVeloctities[car_index]
});
}
}
void UpdateMovements
(
const float inDeltaTime,
vector<MovementDataForCarsToUpdate>& outMovementDataForCarsToUpdate
)
{
for (auto& movement_data : outMovementDataForCarsToUpdate)
{
const Vector2D& pos = movement_data.m_Position;
const Vector2D& dir = movement_data.m_Diretion;
const float vel = movement_data.m_Speed * inDeltaTime;
const Vector2D new_position = pos + dir * vel;
movement_data.m_DistanceTraveled = (pos - new_position).Length();
movement_data.m_Position = new_position;
}
}
void PreapareFuelForCarsToUpdate
(
const vector<unsigned int>& inCarsToUpdate,
const vector<float>& inFuel,
const vector<float>& inFuelConsumptionPerMeter,
const vector<MovementDataForCarsToUpdate>& inMovementDataForCarsToUpdate,
vector<FuelDataForCarsToUpdate>& outFuelDataForCarsToUpdate
)
{
unsigned int movement_data_index = 0;
for (unsigned int car_index : inCarsToUpdate)
{
outFuelDataForCarsToUpdate.push_back
({
inFuel[car_index],
inFuelConsumptionPerMeter[car_index],
inMovementDataForCarsToUpdate[movement_data_index].m_DistanceTraveled
});
++movement_data_index;
}
}
void UpdateFuel
(
const float inDeltaTime,
vector<FuelDataForCarsToUpdate>& outFuelDataForCarsToUpdate
)
{
const float distance = fuel_data.m_DistanceTraveled;
const float fuel_per_meter = fuel_data.m_FuelConsumptionPerMeter;
const float consumed_fuel = distance * fuel_per_meter;
for (auto& fuel_data : outFuelDataForCarsToUpdate)
fuel_data.m_RemainingFuel -= consumed_fuel;
}And finally, let’s have a look at the simulation code. Similarly to the OOD simulation, we are measuring the “ExecuteSimulation(…)” function.
// simulation.cpp
void Simulation(const unsigned int inNumOfFrames,
const unsigned int inNumOfCars)
{
// Create the store
CarsStore store;
// These arrays store simulated input for the cars
vector<float> steering_input;
vector<float> speed_modifications;
PrepareSimulation(inNumOfCars, store, steering_input, speed_modifications);
ExecuteSimulation(inNumOfFrames, inNumOfCars, store,
steering_input, speed_modifications);
}
void PrepareSimulation(const unsigned int inNumOfCars,
CarsStore& inStore,
vector<float>& outSteeringInput,
vector<float>& outSpeedModifications)
{
for (unsigned int car_index = 0; car_index < num_of_cars; ++car_index)
{
// Create a car
// We use random values because they don't matter for this example
const uint64_t id = RandInt();
const auto pos = Vector2D(RandFloat(), RandFloat());
const auto dir = Vector2D(RandFloat(), RandFloat()).Normalized();
inStore.CreateCar(id, pos, dir, RandFloat());
// Deactivate every other car
if (car_index % 2)
inStore.SetCarToDeactivatedState(car_index);
// Add random simulated input that is going to be used to update the cars
outSteeringInput.push_back(RandFloat(-2.5f, 2.5f));
outSpeedModifications.push_back(RandFloat(0.0f, 0.2f));
}
}
void ExecuteSimulation(const unsigned int inNumOfFrames,
const unsigned int inNumOfCars,
CarsStore& inStore,
const vector<float>& inSteeringInput,
const vector<float>& inSpeedModifications)
{
for (unsigned int update_idx = 0; update_idx < inNumOfFrames; ++update_idx)
{
// Damage every other car
for (unsigned int car_index = 0; car_index < num_of_cars; ++car_index)
{
if (car_index % 2 == 0 && !inStore.IsCarDead(car_index))
inStore.DamageCar(car_index, 7.0f);
}
// Update the cars
const float delta_time = RandDeltaTime();
inStore.UpdateCars(delta_time, inSteeringInput, inSpeedModifications);
}
}6.6 – Measurements
To create the executable I used Visual Studio 2019 (v142) toolset.
Before we measure, let me share some information about the hardware I used. I ran the test on two slightly different PCs. We will name the one on the left PC1, and the one on the right PC2. Here are the hardware details for both:

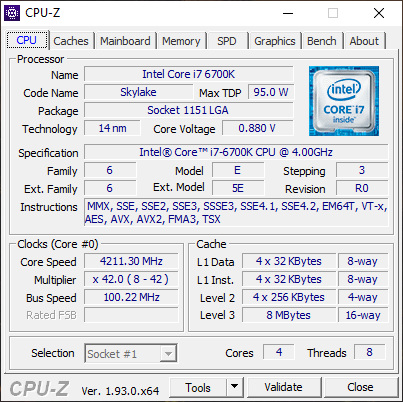
Note that CPU-Z seemed to detect that the Core Speed fluctuated quite a lot (I guess because of some energy saving or cooling) but the values in the screenshot are close to the values on the CPU specifications.
It is time to measure and see the performance of all four approaches. I used the Google Benchmark library for this. The next image shows the result of my measurements.
The Benchmark column holds the name of the measurement and parameters involved in it. For example, OOD_NoInheritanceContMemoryCar/256/60 means that we ran the OOD_NoInheritanceContMemoryCar example, with 256 cars and we simulated 60 game frames.
The Time column holds the time it took to execute the specific example.
For now, we can ignore the CPU and the Iterations columns. The Iteration column might be a bit confusing, but it basically represents how many times the particular test was ran in order to measure the time. By default, Google Benchmark is in control of that and it will base the number of iterations/measurements based on how long it takes to run one measurement. This is the reason why the more cars we simulate the less measurements the library will make. As far as I can tell Google Benchmark tries to normalize the time it takes to measure one case.
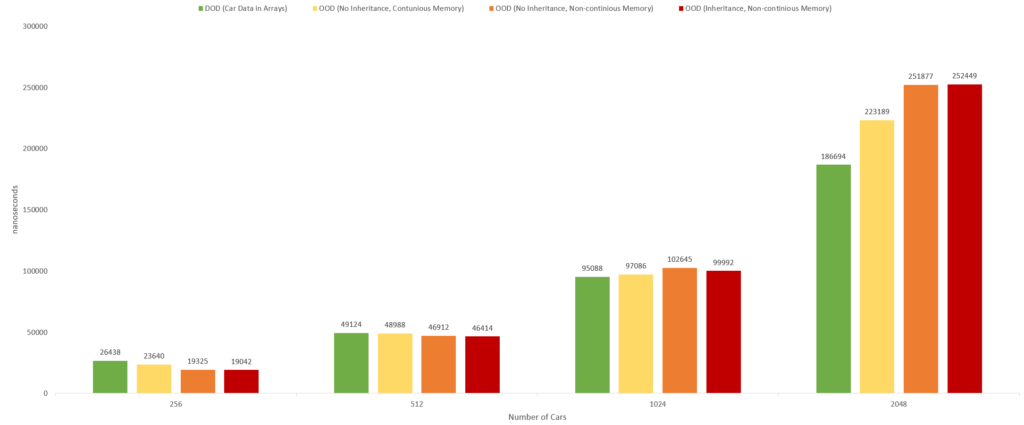
As I mentioned, we will focus mainly on the Benchmark and the Time columns. Here are the results for PC1:

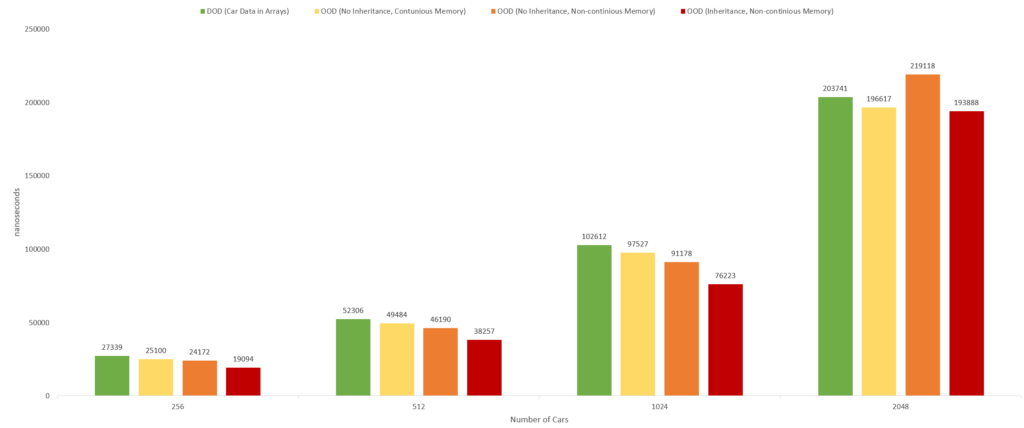
And here are the results for PC2:

Let us plotting the result of the two columns from the benchmark measurements. Here is the chart for PC1:

And here is the chart for PC2:

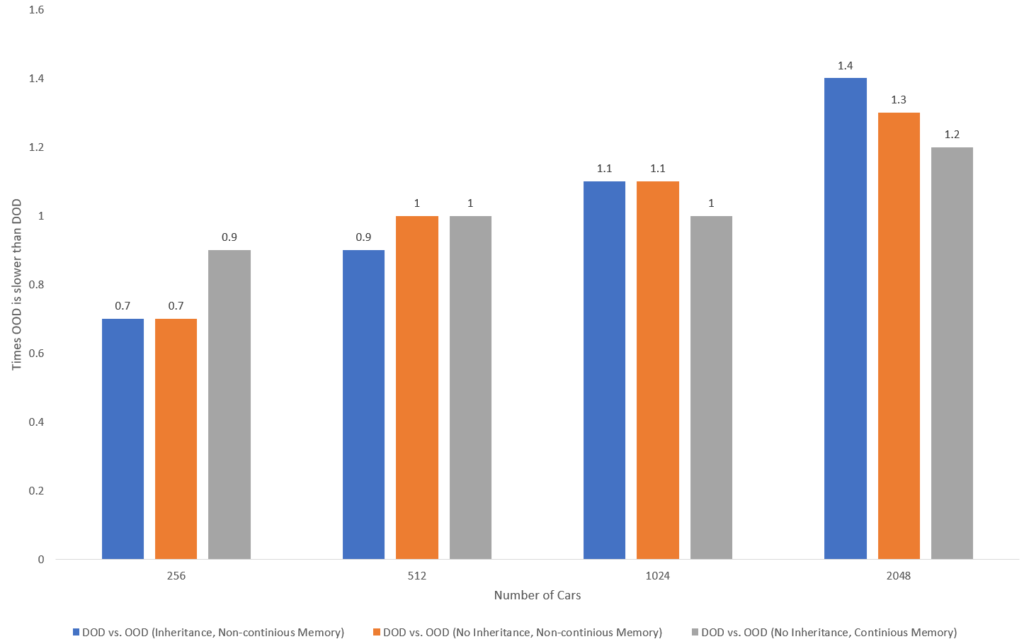
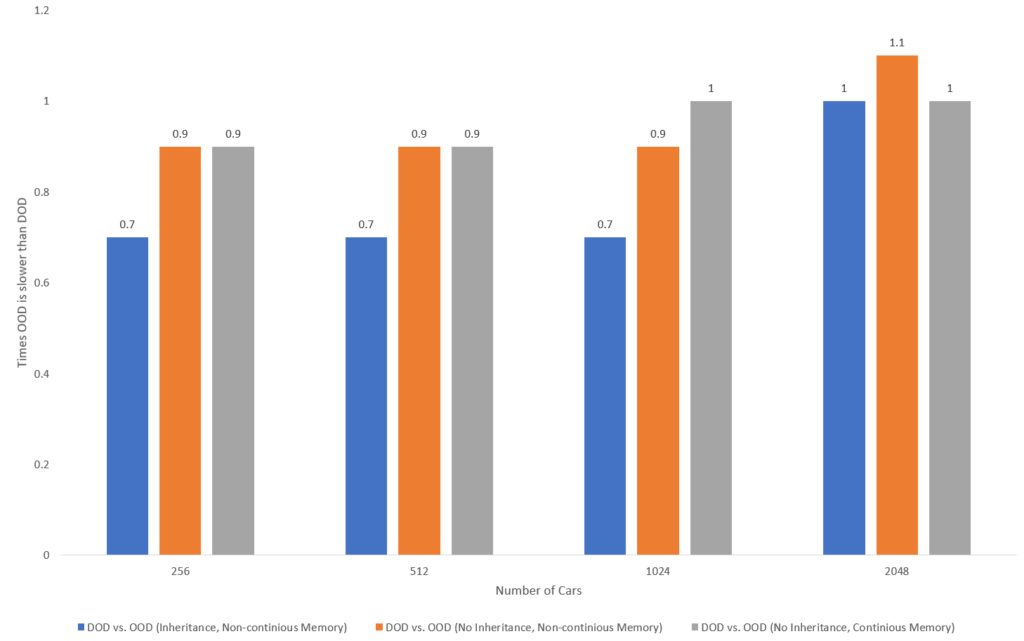
The following charts shows the performance ratio of Approach 4 vs Approach 1,2 and 3. Here is the chart for PC1:

And here is the chart for PC2:

6.7 – Let’s apply the DOD way of thinking to improve Approach 1, 2 and 3
Since the car class is a relatively small one, we can easily spot issues with it. The early out in the following functions can be optimized:
void Car::UpdateSteering(const float inDrivingWheelAngle)
{
if (IsActivated() && HaveFuel() && !IsDead())
// ...
}
void Car::UpdateSpeed(const float inModification)
{
if (IsActivated() && HaveFuel() && !IsDead())
// ...
}
void Car::UpdateMovement(const float inDeltaTime)
{
if (IsActivated() && HaveFuel() && !IsDead())
// ...
}In a small class, with trivial functions, this is quite easy to spot. If it was a medium sized or massive class, it would have been a totally different story. Look at your codebase, or look at software you can find on Github. Millions of code lines exist out there, representing this pattern. Stoyan Nikolov’s Data-oriented design in practice talk at Meeting C++ 2018. This entire talk is about reorganizing data in an already existing commercial software. These early out conditions are a perfect everyday example of how code evolves if we ignore the data. Or at least, that is how I see it.
What we can observe here is a naive last minute decision making. This code is very typical but also quite easy to fix in this particular example. To optimize, we have to pull out the condition from the individual car functions into the simulation code like so:
// simulation.cpp
void ExecuteSimulation(const unsigned int inNumOfFrames,
const unsigned int inNumOfCars,
vector<Car>& inCars)
{
// Random inputs used by the simulation.
const float steering_input = RandFloat(-2.5f, 2.5f);
const float speed_modification = RandFloat(0.0f, 0.2f);
for (unsigned int update_idx = 0; update_idx < inNumOfFrames; ++update_idx)
{
const float delta_time = GetDeltaTime();
for (unsigned int car_index = 0; car_index < inNumOfCars; ++car_index)
{
// Damage every other car
if (car_index % 2 == 0 && !ioCars[car_index].IsDead())
inCars[car_index].TakeDamage(7.0f);
// LOOK HERE: Moving the last minute decision making
// In the inheritance case, we are only moving out the
// !inCars[car_index].IsActivated() and
// inCars[car_index].IsDead() conditions
if (!inCars[car_index].IsActivated() ||
!inCars[car_index].HaveFuel() ||
inCars[car_index].IsDead())
{
continue;
}
// Update the current car
inCars[car_index].UpdateSteering(steering_input);
inCars[car_index].UpdateSpeed(speed_modification);
inCars[car_index].UpdateMovement(delta_time);
}
}
}For the early out optimization to work in the inheritance solutions, we need to move the “HaveFuel()” function from the derived to the base class. This might seem like a minor thing in this small example, but it is not. The potential is big that over time the base class will become a dumping ground for pure virtual functions that are specific to some of the derived classes. The alternative is to pull out only some of the early out conditions while keeping the fuel one in the functions. I choose this option.
void PetrolCar::UpdateSteering(const float inDrivingWheelAngle)
{
if (HaveFuel())
// ...
}
void PetrolCar::UpdateSpeed(const float inModification)
{
if (HaveFuel())
// ...
}
void PetrolCar::UpdateMovement(const float inDeltaTime)
{
if (HaveFuel())
// ...
}It is also important to mention that optimizing the class like this is actually going against some core OOD principles. Moving the conditions out of the functions will cause the class to become unsafe to use, without knowledge of the internals of the class and how you are supposed to use it. Again, this is not a big deal because of the small nature of the test case. In medium to big production classes, this will absolutely be an issue.
These are the new measurements of Approach 1,2 and 3, from PC1 and PC2.
PC1:

PC2:

PC1:
PC2:
PC1:
PC2:
Results are getting quite good with this simple optimization.
By thinking how the data is being used and rearranging it, we can optimize this further. For that to make sense for this example, we need a lot more context and a much bigger test case. Since the class is small we could also split it in two, hot and cold data. It works for our small example, but what is cold data in one data transformation could be hot in another. And some sort of combination of the hot and cold might be hot data for yet another data transformation. In any case, we could get Approach 1, 2 and 3 extremely close to the performance of Approach 4. Sometimes they are even faster. This is because the extra copies in Approach 4 are noticeable when cache utilization is similar.
As I mentioned before, the inheritance examples are a bit harder to optimize in terms of early outs and data organization. It is also harder to improve, when it comes to the data organization as well. While we have control over the details of the derived class, we don’t always have full freedom and visibility of the consequences of rearranging and splitting data in the base classes, since that data might be used by many derived classes and data transformations.
When it comes to the examples with non-continuous memory, the only optimization there is to make it continuous. It is not that easy when it comes to data that could be instantiated at any time while the software is running. To do so, we can utilize custom allocators or we need to come up with some sort of a store with slots that will make sure that newly allocated data is nicely allocated in a continuous block. ECS could offers some tools for the latter.
We can also further optimize Approach 4. We can in fact reduce the data copies quite a lot with ECS. To some degree ECS will eliminate the need for most of the transient data. That being said, the code of Approach 4 is bigger. It introduces concepts like the store, that might be foreign for a lot of programmers. And of course for small problems, this solution is probably an overkill because of the extra copies and internal data transformations. And so, you have to think about your data. It is not easy to say: use A, B, C tools or techniques for problems X, Y, Z. It is just not a clean cut.
6.8 – Other test cases
There is another test case included in the source code for this article. That other test demonstrates another very common situation, which is calculating a value that is based on a formula that requires data that is spread around in an object. You can find the download link the end. To reduce the size of the article I chose to not go into details about this other test case. I encourage you to download the source code and play around with both test cases.
7 – Conclusion
The evolution of hardware is not matched by the evolution of software. The three main programming schools, have been with us for many decades now. There is way more investment in the hardware and naturally it evolves very fast. And that is ok. It is not obvious to me that the programming languages should evolve as quickly as the hardware.
Many times I’ve heard that all of our problems will be solved if C++ would have this and that feature. Or if we can get a copy of some feature from Python or D. Or if the language can evolve in this or that way. I just don’t believe that to be the ulimate solution. Being aware of the data allows us to write code that takes advantage of the evolution of the hardware in a more direct way, while still using all of our familiar language features. When our target hardware changes drastically, the problem changes with it. A great example for this is the PS3 to PS4 transition.
I work for an industry where I’m solving a range of very different and some quite difficult challenges. Sometimes this leads to typical DOD techniques like ECS, other times to small and simple objects. If I don’t take full advantage of the the hardware and the tools I have, and if my code is hard to understand by other programmers and hard to reason about in terms of parallelization and performance, then I’m doing something wrong. In that case, I’ll be limiting the creative output of my colleagues.
The DOD way of thinking allows me to solve problems in a way where I think about the data transformation, about the most statistically common data transformations, and about how the target hardware will execute my code and about how other programmers will interact my code.
DOD doesn’t negate OOD concepts, in fact it can work alongside them. We saw how we can apply DOD and think about the data to improve all test case approaches. When dealing with small classes, it is very easy to arrange your data based on the access patterns and gain performance benefits. The first version of Approach 1, 2 and 3 was made in a way to try to simulate the evolution of a typical codebase over the course of many months and years. The bigger and the more encompassing a class is, the harder it is to spot the the issues. I’ve made those examples in this particular way to illustrate how easy things can go wrong. And they can go wrong very easily in bigger classes with more complicated functions that read more data and that branch more.
Unfortunately the test case we examined is not big enough to represent a real world codebase. I can only talk about my personal experience, but I have seen way too many massive classes, composed of a lot of data, with massive functions, with repeating early outs embedded at various locations and scopes in the functions, with lots of last minute decision making and cache misses. And unfortunately, I’ve seen way too many classes that start small and simple and rapidly evolve into monsters over the course of a project. Continuously thinking about our data and knowing about the hardware our data transformations will run on, will help us make better decision about how to structure, change and support our data structures over long periods of time.
In my experience, I found that “typical DOD” solutions, like ECS or the one I wrote in Approach 4, will scale very well and in a predictable way for problems that take on large amounts of data (many instances of the same types of data) and with lots of computations and branching involved, as well as with highly parallel traits. Good examples from the gaming industry are: AI, Animation, Rendering and certain gameplay systems.
In my experience, I also found that concepts used in Approaches 1,2 and 3 in the cars test case, are good tools as well. Especially when we apply DOD thinking to them and when we are not dealing with large amounts of data. Everything I said about the overuse of OOD concepts and taking them to the extreme, which unfortunately happens quite often, is a big concern I personally have. I’m yet to see a medium or large class, that many programmers iterated on for many months or years, to maintain good OOD practices and to keep the data in mind. And in all fairness I’m also concerned by the overuse of DOD concepts, like ECS. It is useful, but could be dangerous when used inappropriately.
And finally, please always profile your code on your target hardware or range of hardware. There will be differences, even on similar hardware. Even better if you try to understand why the differences exist, it will help you down the road. Always measure and always consider what is the right tool for the job!
8 – References and Useful Materials
The source code for the cars test case, as well as another test case, is here (under DataOrientedDesign). You do not need a Github account to download it. When you open the repository, click on the Code button and choose Donwload ZIP.
- Mike Acton’s Data Oriented Design and C++ talk at CppCon 2014 and slides
- What Every Programmer Should Know About Memory
- Stoyan Nikolov’s Data-oriented design in practice talk at Meeting C++ 2018 and slides
- Pitfalls of Object Oriented Programming, Tony Albrecht, SONY
- Pitfalls of Object Oriented Programming – Revisited, Tony Albrecht, Riot Games, TGC2017
- Understanding data-oriented design for entity component systems, Unity at GDC 2019
- Introduction to Data Oriented Design, FROSTBITE, EA
- Introduction to Data-Oriented Design, Yaroslav Bunyak, SoftServe
- A Data-Oriented Programming Paradigm for Optimal Performance, Milo Yip, Tencent
- Memory Optimization, Christer Ericson, SCE Santa Monica
- Practical Examples in Data Oriented Design, Niklas Frykholm, BitSquid
- Know Your Architecture: Performance Programming for Gamedev Students, Keith O’Conor, Ubisoft Montreal
- Cpu Caches and Why You Care, Scott Meyers at code::dive conference 2014
9 – Credit
Special thanks to my colleagues for spending their personal time proofreading, challenge this article and helping me to make it better. It is a pleasure working with every one of you!
- Angelos Kremyzas: AI Programmer at IO Interactive.
- Anton Andersson: Senior Gameplay Programmer at IO Interactive.
- Maurizio De Pascale: CTO at IO Interactive.
- Nils Iver Holtar: Lead AI Programmer at IO Interactive.
- Thomas E. Petersen: Senior AI Programmer at IO Interactive.
Please consider sharing this post if you find the information useful.